Symbolic Artificial Intelligence, Semantic Web
State of the art
The Semantic Web project was formulated at the end of the 20th century and is based on the availability of inference engines and ontologies (rule-based systems representing domain knowledge) that were developed at the time as the “expert systems” in the 1970s and 1980s. However, at the time not all computers were interconnected and the problem of semantic interoperability was not as acute as it is today. Yes, the Semantic Web makes it possible to compute semantic relationships and make logical inferences, but only within an ontology. The problem is that there are thousands of different existing ontologies and translations between ontologies must be done “by hand.”
The problem of semantic interoperability
Semantic interoperability is about concepts, while format interoperability is about the compatibility of digital files. The problem of format interoperability can be considered solved by Web standards (in particular by the system of URLs, HTML, XML, and RDF), by APIs between applications, and by service architectures that feed several distinct applications.
On the other hand, in 2021, the problem of semantic interoperability has not yet been solved. There are many causes for the opacity that burdens digital memory. Natural languages are multiple, informal, ambiguous, and changing. Cultures and disciplines divide reality in different ways. And the numerous metadata systems used to classify data – often inherited from the age of print – are incompatible. By metadata systems we mean: thesauri, documentary languages, ontologies, taxonomies, folksonomies, sets of tags or hashtags, keywords, column and row headings, etc.
The solution of semantic Interoperability
In IEML, semantic interoperability comes from the fact that everyone may share the same set of words, whose meanings are fixed, and the same IEML grammar. IEML, being both a formal and a quasi-natural language, computes, generates, and recognizes automatically an infinity of concepts and their semantic relations. IEML is not a universal ontology (like Cyc, for example), it is a language with computable semantics that can express any kind of ontology or knowledge graph and can make them comparable and combinable.
Problems in ontology management and ontology edition solved by IEML
The World Wide Web Consortium project represents semantic relationships by means of logical formalism and its nodes are arbitrary sequences of characters (like URLs). In contrast, IEML represents semantic relationships through linguistic formalism with nodes (USLs, or Uniform Semantic Locators) that are expressions of a single regular language. Because they are composed of IEML phrases, semantic relationships are represented here in a much more parsimonious way. IEML graphs are easy to decompose, recompose, and merge.
Innovation in ontology edition: the IEML paradigmatic spreadsheet
The regular and functional nature of IEML USLs allows the implementation of a new method for the edition and maintenance of metadata systems (classification, thesaurus or ontology). Multiple concepts in the same semantic domain can be expressed by a semantic function combining constants and variables. The constants represent the semantic features shared by all concepts in this semantic domain, and the variables represent the range of semantic differences between the concepts. The function – including constants and variables – that generates the concepts of a domain (or a subdomain) is called a paradigm. When the variation involves several parts of the USLs, it can be represented by a multidimensional array, where each cell is a USL of the domain, and the cell headers represent the sum of the variable components.
Example of an IEML paradigm
While traditional methods involve the visualization of complex graphs, IEML ontologies are explored and edited by means of a semantic spreadsheet that allows the constants and variables of a semantic domain to be visualized by easily understandable tables.
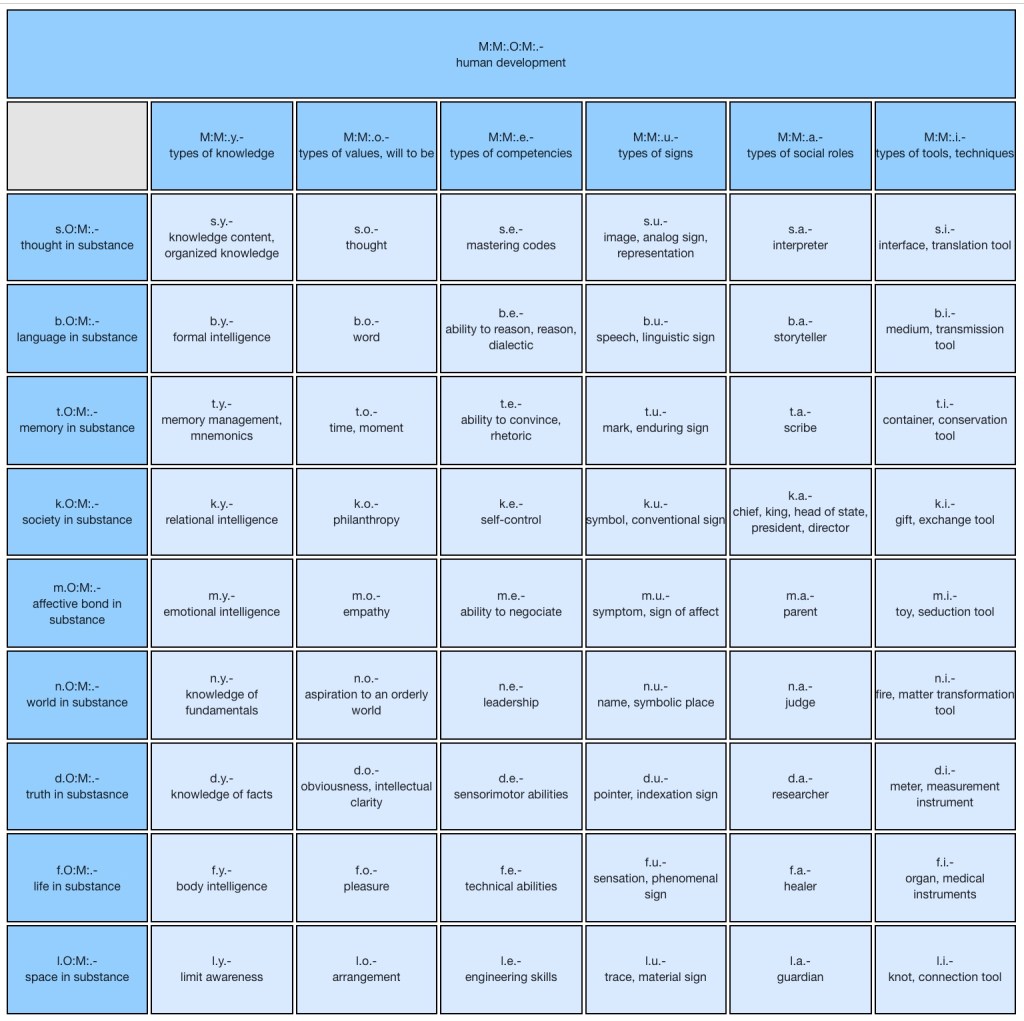
In the above table, the IEML codes having the same substance are in the same row and the codes having the same attribute are on the same column. The punctuation mark « . » means « second layer » and the punctuation mark “–” means “third layer”. The reader can easily see that a row or a column contains concepts that have some meaning in common and that the common semantic feature is represented in IEML by the same character.
Advantages brought by the paradigmatic spreadsheet
An IEML paradigm stands for a synthesis of a semantic domain, and helps grasping the meaning of the cells by their mutual relationships. This view also facilitates the maintenance of consistency in an ontology by providing a high level point of view on the diversity of concepts.
The above table is at the level of words, where a word is situated in one single paradigmatic table. At the level of radicals and phrases, a USL can be represented by a cell in different tables, and its meaning arises from the intersection of the associated semantic domains of each table.
Traditional methods using natural languages to express categories and relations in an ontology involve their creation by hand and one by one. By contrast, the IEML editor automates the generation of categories and their relationships. For example, the 2D matrix and IEML codes of the human development Table have been automatically generated by the paradigmatic fonction M:M:.O:M:.-
The IEML editor encourages its user to design a general model of a semantic domain and then define the particular concepts (top-down). It is not the approach that is generally favored by current semantic editors, that go from isolated concepts to an a-posteriori uniformized whole (bottom-up). Our paradigmatic approach helps the ontologist or metadata scientist to keep his work coherent.
Ontology and knowledge graph merging
Problem
Knowledge graphs are constructed by aggregating a multitude of diverse data sources. Most of the time, data sources are organized by different and often incompatible metadata systems (schemas or ontologies). The role of the data curator (or data scientist) is to merge the schemas or ontologies of each source into a coherent meta-ontology. During this process, some common problems emerge: (1) concepts from different sources that at first glance appear to mean the same thing turn out to be different and (2) different words represent in fact identical concepts. In case (1) the curator is faced with an alternative: either he chooses to merge the concepts into a larger and simpler category, but then loses the specificity of each source, or he can choose to maintain the distinction, at the cost of a more complex ontology. In case (2) if the problem is not spotted, the result could be a redundant and inaccurate metadata system. The larger the knowledge graph is, the more acute are the problems.
Solution
The aforementioned problems are mainly due to imprecise category naming.
- In IEML, the categories, particularly at the level of the phrase, are self-explanatory.
- Different concepts (such as homonyms, concepts that share the same words but not the same meaning) are clearly distinguished.
- Identical categories are represented by an identical semantic code (USL).
IEML resolves the merging of ontologies by always keeping the distinction between concepts, but without crippling the resulting ontology by increasing its complexity or redundancy. All nodes are expressed in the same language, and new concepts are understandable without the need of external resources (like a http triple store for RDF). Ontologies may simply be added together and the merge is semi-automatic. Because they are created by functions, the semantic links that are already applied in one ontology are automatically applied in the second, potentially enriching the data structure. If necessary, in order to bridge some gap between the ontologies, the data curator may create some new functions determining semantic relationships in the new unified knowledge graph.
Natural language processing
Problem
Computers read a text as we would see a foreign written language: a compilation of unknown symbols. Unlike us, a computer cannot interact with the real world and link the written word to a tangible referent. We can give explanations and representations in the form of logical connections and knowledge bases, but they are, themselves, written in the same indecipherable way.
Deep-learning models are state-of-the-art algorithms that have shown to surpass previous methods for many computable tasks. Its success in natural language processing (NLP) lies in the way it represents text. Instead of just considering the text as it is, they are trained to represent each word as a fixed-length feature vector. These vectors try to encode the semantic and syntactic properties of sentences by giving a representation of the usual neighbors of said words. The idea being that words with similar meanings occur in similar contexts. Nevertheless, no matter how much detail is given, the data is always based on the same written characters that contain no meaning and are, therefore, illegible to a computer.
Solution
That is the gap that IEML fills. Our system uses characters as a representation of the meaning, instead of using them as a representation of the sound. We start with 6 basic concepts whose inter-combination creates slightly more complex concepts which, in turn, can be recombined to form even more complex ones and so on. The semantic complexity of a concept is theoretically boundless but IEMl is designed to be space-saving and easy to process by a computer.
In pure statistical AI, a computer that wields and changes the characters of a word would only be toying with its written form, made to represent its sound. But if we were to use IEML, to change one character is to manipulate its meaning. This would drastically change the purpose of « learning » in AI and means a great advancement into helping a computer understand what idea is behind each word.
Automatic categorization
Problem
Machine learning systems (statistical AI) are used to categorize automatically text, documents and images. Statistical models often rely on large dataset of human annotated data. The annotation of the data takes a lot of human effort and the results of a particular annotation are often incompatible with some other annotation, because they use different annotation systems and different natural languages. The systems of labels affixed to data for training statistical models are not unified. Then, it makes the merging of such dataset often impossible or very difficult.
Solution
IEML allows disparate datasets to be merged into a unified metadata system. The dataset produced for a specific task can also be used to train models on related tasks. Machine learning architectures that produce IEML expressions are adaptable to new tasks because the output format does not change, only the content of the IEML expression.
The exchange and recycling of datasets that are tagged in IEML are facilitated and open the prospect of a semantically unified dataset marketplace.
The unification of labeling systems with IEML also facilitates the work of the data labeler by reducing the number of metadata systems to be learned. Finally the semantic accuracy of IEML expressions allows a better handling of labeling exceptions for rare values.
