Abstract
The goal of this essay is to present an overview of the limitations of contemporary AI (artificial intelligence) and to propose an approach to overcome them with a computable semantic metalanguage. AI has made considerable progress since the time of Claude Shannon, Alan Turing, and John von Neumann. Nevertheless, many obstacles have appeared on the road paved by these pioneers. Today, symbolic AI is rooted in conceptual modeling and automatic reasoning, while neural AI excels in automatic categorization; however, both the symbolic and neural approaches encounter many problems. The combination of the two branches of AI, while desirable, fails to resolve either the compartmentalization of modeling, or the challenges of exchanging and accumulating knowledge.
Innate human intelligence solves these problems with language. Therefore, I propose that AI adopts a computable and univocal model of the human language, the Information Economy Metalanguage (IEML), a semantic code of my own invention. IEML has the expressive power of a natural language and the syntax of a regular language. Its semantics are unambiguous and computable because they are an explicit function of its syntax. A neuro-semantic architecture based on IEML combines the strengths of neural AI and classical symbolic AI while enabling integration of knowledge through an interoperable computing of semantics. This can open new avenues for Artificial Intelligence to create a synergy between the democratization of data control and the enhancement of collective intelligence.
Bibliographical references and links for further reading are located at the end of this essay.
Introduction
Let’s first examine how the term « artificial intelligence » (AI) is used in society at large, for example in journalism and advertising. Historical observation reveals the tendency to classify the “advanced” applications into artificial intelligence in the eras in which they first emerge; however, years later, these same applications are often reattributed to everyday computing. For example, visual character recognition, originally known to be AI, is now considered to be commonplace and is often integrated into software programs without fanfare. A machine capable of playing chess was celebrated as a technical achievement in the 1970s, but today you can easily download a free chess program onto your smartphone without a hint of astonishment from anyone. Moreover, depending on whether AI is trendy (as it is today) or discredited (as it was in the 1990s and 2000s), marketing strategies will either emphasize the term AI or replace it with others. For example, the « expert systems » of the 1980s become the innocuous « business rules » in the 2000s. This is how identical techniques or concepts change name according to the fashion, making the perception of the domain and its evolution particularly opaque.
Let’s now leave the vocabulary of journalism or marketing to investigate academic discipline. Since the 1950s, the designated branch of computer science that is concerned with modeling and simulating human intelligence is called Artificial Intelligence.
Computer modeling of human intelligence is a worthy scientific goal that has had, and will continue to have, considerable theoretical and practical benefits. Nevertheless, most researchers in the field do not believe that autonomous intelligent machines will soon be built, notwithstanding the early, enthusiastic predictions about AI’s capability declared in the early years that were later contradicted by the facts. Much of the research in this field – and most of its practical applications –is aimed at augmenting human cognition rather than mechanically reproducing it. This is in contrast to the program of research focused on the construction of an autonomous general Artificial Intelligence.
I have defended the idea of Artificial Intelligence in the service of collective intelligence and human development in my book, La Sphère Sémantique. Let’s continue this line of thought here in this essay.
From a technical perspective, AI is split into two main branches: statistical and symbolic. A statistical AI algorithm « learns » from the supplied data. It therefore simulates (imperfectly, as we will see below) the inductive dimension of human reasoning. In contrast, symbolic AI does not learn from data, rather it depends on the logical formalization of a domain of knowledge as designed by engineers. In principle, compared to statistical AI, it therefore demands a greater amount of human intellectual work. A symbolic AI algorithm applies the rules it was given to the supplied data. Hence, it simulates more of the deductive dimension of human reasoning. I will successively review these two main branches of AI, with a particular focus on underlining their limitations.
AI and its limitations
Neural AI
The statistical branch of AI involves the training of algorithms from massive accumulations of data to enable the recognition of visual, audio, linguistic and other form of information. This is called machine learning. When we talk about AI in 2022, we generally designate this type of technical and scientific research program. As we have observed, statistical AI uses human labor sparingly in comparison to symbolic AI. Instead of having to write a pattern recognition program, it suffices to provide a set of training data for the machine learning algorithm. If, for example, statistical AI is given millions of images of ducks with labels specifying that the image represents a duck, it learns to recognize a duck and, upon completion of its training, will be able to affix the label « duck » on an uncategorized image of that bird. Nobody explained to the machine how to recognize a duck: it is enough to simply give it examples. Machine translation works on the same principle: a statistical AI is given millions of texts in language A, accompanied by their translation into language B. Trained with these examples, the system learns to translate a text from language A into language B. This is how machine translation algorithms like DeepL or Google Translate work. To take an example from another field, the statistical AI used to drive « autonomous vehicles » also works by matching two sets of data: images of the road are matched with actions such as accelerating, braking, turning, etc. In short, statistical AI establishes a connection (mapping) between a set of data and a set of labels (in the case of pattern recognition) or between two sets of data (in the case of translation or autonomous vehicles). Statistical AI therefore excels in categorization, pattern recognition and matching between perceptual and motor data.
In its most advanced version, statistical AI is rooted in neural network models that roughly simulate the way the brain learns. These models are called « deep learning » because they are based on the overlapping of multiple layers of formal neurons. Neural networks are the most complex and advanced sub-field of statistical AI. This neural type of artificial intelligence has been around since the origin of computer science, as illustrated by the research of McCulloch in the 1940s and 50s, Frank Rosenblatt and Marvin Minsky in the 1950s, and von Foerster in the 1960s and 70s. Significant work in this area was also done in the 1980s, especially involving David Rumelhart and Geoffrey Hinton, among others, but all this research had little practical success until the 2010s.
Besides certain scientific refinements of the models, two factors independent of theoretical advances explain the growing use of neural networks: the availability of enormous amounts of data and the increase in computing power. Starting in the second decade of the 21st century, organizations are engaged in digital transformation and a growing share of the world’s population is using the Web. All this generates gargantuan data flows. The information thus produced is processed by large digital platforms in data centers (the « cloud ») that concentrate unprecedented computing power. At the beginning of the 21st century, neural networks were implemented by processors originally designed for computer graphics, but nowadays, the data centers owned by Big Tech already use processors specifically designed for neural learning. Thus, interesting but impractical theoretical 20th century models have suddenly become quite relevant in the 21st century, to the point of supporting a new industry.
Artificial intelligence or synthesis and mobilization of data?
The year 2022 has seen the triumph of what is called generative AI. Models trained on huge masses of data are able to produce texts (ChatGPT) or images (DALLE2, Stable Diffusion, etc.) of amazing quality. It is possible to control the output by means of « prompts » and, increasingly, by a dialogue allowing the user to send feedback to these systems. It is clear that these are remarkable advances in the field of software and the applications are already numerous, especially in the field of augmented creativity and pattern recognition. But the name « artificial intelligence » that is given to these systems can be misleading. It is enough to interact a little with ChatGPT to realize that the model does not really understand what it is told, nor the texts it produces: errors of logic or elementary arithmetic, factual errors, ethical monstrosities and other « hallucinations » (which Twitter users amuse themselves with) underline the limits of the purely statistical approach. I agree that these new tools, by synthesizing and mobilizing the content of huge databases, are capable of increasing or replacing human work. They do announce a new wave of automation with economic and cultural consequences that are still difficult to predict. But we are far from an autonomous intelligence capable of a true knowledge or understanding of the world. And it seems that more data, more parameters (number of internal connections to the model), and more computing power are not able to remedy the root of the problem.
The main problems rest in the quality of training data, the lack of causal modeling, the inexplicable nature of some of the results, the absence of generalization, the reportedly inscrutable meaning of the data, and finally, the difficulties in accumulating and integrating knowledge.
Quality of Training Data
A Google engineer is quoted as saying jokingly, « Every time we fire a linguist, our machine translation performance improves. » But while statistical AI is known to have little need for human labor, the risks of bias and error pointed out by increasingly concerned users are driving the need for better selection of training data including more careful labeling. Yet, this requires time and human expertise, precisely the factors that one is hoping to eliminate.
Absence of an Explicit Causal Hypotheses
All statistics courses start with a warning about the confusion between correlation and causation. A correlation between A and B does not prove that A is the cause of B. It may be a coincidence, or B may be the cause of A, or even a factor C not considered by the data collection is the real cause of A and B, not to mention all the complex systemic relationships imaginable involving A and B. Yet, machine learning is based on matching datasets through correlations. The notion of causality is foreign to statistical AI, as it is with many techniques used to analyze massive data collections, even though causal assumptions are often implicit in the choice of datasets and their categorization. In short, contemporary neural/statistical AI is not capable of distinguishing cause from effect. So far, when using AI to assist with decision making and more generally for orientation in practical domains, explicit causal models are indispensable, because for actions to be effective they must intervene on the causes.
In an integral scientific approach, statistical measurements and causal hypotheses work in unison and reciprocate control. But to only consider statistical correlations would create a dangerous cognitive blind spot. As for the widespread practice of keeping one’s causal theories implicit, it prevents relativizing them, comparing them with other theories, generalizing, sharing, criticizing, and improving them.
Inexplicable Results
The functioning of neural networks is opaque. Millions of operations incrementally transform the strength of connections of neural assemblies which themselves are made of hundreds of layers.
Since the results of these operations cannot be explained or justified conceptually in a way that humans can understand, it is difficult to trust these models. This lack of explanation becomes worrisome when machines make financial, legal, medical, or autonomous vehicle driving decisions, not to mention military applications. To overcome this obstacle, and in parallel with the development of a more ethical artificial intelligence, more and more researchers are exploring the new research field of « explainable AI ».
The Lack of Generalization
At first glance, statistical AI presents itself as a form of inductive reasoning, i.e., as an ability to infer general rules from a multitude of cases. Yet contemporary machine learning systems fail to generalize beyond the limits of the training data with which they have been provided. Not only are we – humans – able to generalize from a few examples, whereas it takes millions of cases to train machines, but we can abstract and conceptualize what we have learned while machine learning fails to extrapolate, let alone, conceptualize. Statistical AI remains at the level of purely reflex learning, its generalization narrowly circumscribed to the supplied examples with which it is provided.
Inaccessible Meaning
While performance in Machine translation and automatic writing (as illustrated by the GPT3 program) is advancing, machines still fail to understand the meaning of the texts they translate or write. Their neural networks resemble the brain of a mechanical parrot only capable of imitating linguistic performance without understanding an iota of the content of the texts it is translating. In a nutshell, contemporary Artificial Intelligence can learn to translate texts but is unable to learn anything from these translations.
The Problem of Accumulation and Integration of Knowledge in Statistical AI
Bereft of concepts, statistical AI has difficulty in accumulating knowledge. A fortiori, the integration of knowledge from various fields of expertise seems out of reach. This situation does not favor the exchange of knowledge between machines. Therefore, it is often necessary to start from scratch for each new project. Nevertheless, we should point out the existence of natural language processing models such as BERT, which are pre-trained on general data, and which then have the possibility of specializing. A form of capitalization is possible in a limited fashion. But it remains impossible to integrate all the objective knowledge accumulated over the centuries by humanity into a neuro-mimetic system.
Symbolic AI and its Limits
During the last seventy years, the symbolic branch of AI has successively corresponded to what has been known as: semantic networks, rule-based systems, knowledge bases, expert systems, semantic web and, more recently, knowledge graphs. Since its origins in the 1940s-50s, a good part of computer science de facto belongs to symbolic AI.
Symbolic AI encodes human knowledge explicitly in the form of networks of relations between categories and logical rules that enable automatic reasoning. Its results are, therefore, more easily explained than those of statistical AI.
Symbolic AI works well in the closed microworlds of games or laboratories, but quickly becomes overwhelmed in open environments that do not follow a small number of strict rules. Most symbolic AI programs used in real-world work environments solve problems only in a narrowly limited domain, whether it’s medical diagnosis, machine troubleshooting, investment advice, etc. An « expert system, » in fact, functions as a medium for the encapsulation and distribution of a particular know-how which can be distributed wherever it is needed. The practical skill then becomes available even in the absence of human expertise.
At the end of the 1980s, after a series of ill-considered promises followed by disappointments began what has been called the « winter » of artificial intelligence (all trends combined). However, the same processes continue to be applied to solve the same types of problems indiscriminately We have only abandoned the general research program in which these methods were embedded. Thus, at the beginning of the 21st century, the business rules of enterprise software and the ontologies of the Semantic Web have succeeded the expert systems of the 1980s. Despite the name changes, it is easy to recognize in these new specialties the old processes of symbolic AI.
In the early 2000s, the Semantic Web has been aimed at exploiting all the information available on the Web. To make the data readable by computers, different domains of knowledge or practice are organized into coherent models. These are the « ontologies », which can only reproduce the logical compartmentalization of previous decades, even though computers are now much more interconnected.
Unfortunately, we find in symbolic AI the same difficulties in the integration and accumulation of knowledge as in statistical AI. This compartmentalization is in opposition with the original project of Artificial Intelligence as a scientific discipline, which wants to model human intelligence in general, and which normally tends towards an accumulation and integration of knowledge that can be mobilized by machines.
Despite the compartmentalization of its models, symbolic AI is, however, slightly better off than statistical AI in terms of accumulation and exchange of data. A growing number of companies, starting with the Big Tech companies, are organizing their databases by using a knowledge graph which is constantly being improved and augmented.
Moreover, Wikidata offers a good example of an open knowledge graph through which the information that is gradually accumulating can be read just as well by machines as it can be by humans. Nevertheless, each of these knowledge graphs is organized according to the – always particular – purposes of its authors and cannot be easily reused to other ends. Neither statistical AI nor symbolic AI possess the properties of fluid recombination that we should rightly expect from the modules of an Artificial Intelligence at the service of collective intelligence.
Symbolic AI is a Voracious Consumer of Human Intellectual Work
There have been many attempts to contain all human knowledge in a single ontology to allow better interoperability, but then the vibrancy, complexity, evolution, and multiple perspectives of human knowledge are erased. On a practical level, universal ontologies – or even those that claim to formalize all the categories, relations, and logical rules of a vast domain – quickly become huge, cumbersome, and difficult to understand and maintain for the human who must deal with them. One of the main bottlenecks of symbolic AI is the quantity and high quality of human work required to model a domain of knowledge, however narrowly circumscribed. Indeed, not only is it necessary to read the literature, but it is also necessary to interview and listen at length to several experts in the domain to be modeled. Acquired through experience, the knowledge of these experts is most often expressed through stories, examples, and descriptions of typical situations. It is then necessary to transform empirical, oral knowledge into a coherent logical model whose rules must be executable by a computer. Eventually, the reasoning of the experts will be automated, but the « knowledge engineering » work from which the modeling proceeds cannot be.
Problem Position: What is the Main Obstacle to (Further) AI Development?
Towards a Neuro-symbolic Artificial Intelligence
It’s now time to take a step back. The two branches of AI – neural and symbolic – have existed since the middle of the 20th century and they correspond to two cognitive styles that are equally present in humans. On the one hand, we have pattern recognition, which corresponds to reflex sensorimotor modules, whether these are learned or of genetic origin. On the other hand, we have explicit and reflective conceptual knowledge, often organized in causal models and which can be an object of reasoning.
Since these two cognitive styles work together in human cognition, there is no theoretical reason not to attempt to make them cooperate in Artificial Intelligence systems. The benefits are obvious and each of the two subsystems can remedy problems encountered by the other. In a mixed AI, the symbolic component overcomes the difficulties of conceptualization, generalization, causal modeling, and transparency of the neural component. Symmetrically, the neural component brings the capabilities of pattern recognition and learning from examples that are lacking in symbolic AI.
Both important AI researchers and many knowledgeable observers of the discipline are gravitating in the direction of a hybrid AI. For example, Dieter Ernst recently advocated an “integration between neural networks, which excel at perceptual classification and symbolic systems, which in turn excel at abstraction and inference”. [1]
Following in the footsteps of Gary Marcus, AI researchers, Luis Lamb and Arthur d’Avila Garcez, recently published a paper in favor of a neuro-symbolic AI in which representations acquired by neural means would be interpreted and processed by symbolic means. It seems that we have found a solution to the problem of the blockage in AI development: it would be beneficial to intelligently couple the symbolic and statistical branches rather than keeping them separate as two competing research programs. Besides, don’t we see the Big Tech companies, which highlight machine learning and neural AI in their public relations efforts, discreetly developing knowledge graphs internally to organize their digital memory, and to make sense of the results of their neural networks? But before we declare the issue settled, let’s think a little more about the givens of the problem.
Animal Cognition and Human Cognition
For each of the two branches of AI, we have listed the obstacles that stand in the way of a less fragmented, more useful, and more transparent Artificial Intelligence. Yet, we found the same drawback on both sides: logical compartmentalization, and the difficulties of accumulation and integration. Bringing together the neural and the symbolic will not help us to overcome this obstacle, since neither of them can do so. Yet, actual human societies can transform tacit perceptions and experiential skills into shareable knowledge. By dint of extensive dialogue, a specialist in one field will eventually make himself understood by a specialist in another field and may even teach him something. How can this kind of cognitive performance be reproduced in machine societies? What factor plays the integrative role of natural language in Artificial Intelligence systems?
Many people think that since the brain is the organic receptacle of intelligence, neural models are the key to its simulation. But what kind of intelligence are we talking about? Let’s not forget that all animals have a brain, and it is not the intelligence of, for example, the gnat or the whale that AI wants to simulate, but that of the human being. And if we are « more intelligent » than other animals (at least from our point of view) it is not because of the size of our brain. Elephants have bigger brains than humans in absolute terms, and the ratio of brain size to body size is greater in mice than in humans. It is mainly our linguistic capacity, predominantly processed in the Broca and Wernicke areas of the brain (unique to the human species), that distinguishes our intelligence from that of other higher vertebrates. However, these language processing modules are not functionally separate from the rest of the brain; on the contrary, they inform all our cognitive processes, including our technical and social skills. Our perceptions, actions, emotions, and communications are linguistically coded, and our memory is largely organized by a system of coordinated semantics provided by language.
That’s fine, one might say. Isn’t simulating human symbolic processing abilities, including the linguistic faculty, precisely what symbolic AI is supposed to do? But then, why is it that AI is compartmentalized into distinct ontologies, yet it struggles to ensure the semantic interoperability of its systems, and it has much difficulty in accumulating and exchanging knowledge? Simply because, despite its name of « symbolic, » AI still does not have a computable model of language. Since Chomsky’s work, we know how to calculate the syntactic dimension of languages, but their semantic dimension remains beyond the reach of computer science. To understand this situation, it is necessary to recall some elements of semantics.
Semantics in Linguistics
From the viewpoint of the scientific study of language, the semantics of a word or a sentence can be broken down into two parts which are combined in practice, yet conceptually distinct: linguistic semantics and referential semantics. Linguistic semantics deals with the relationship between words, while referential semantics is concerned with the relationship between words and things.
Linguistic Semantics (word-word). A linguistic symbol (word or sentence) generally has two aspects: the signifier, which is a visual or acoustic image, and the signified, which is a concept or a general category. For example, the signifier « tree » has the following meaning: « a woody plant of variable size, whose trunk grows branches starting at a specific height ». Given that the relationship between signifier and signified is established by a language, the signified of a word or a sentence is defined as a node of relationships with other signifieds. In a classical dictionary, each word is situated in relation to other associated words (the thesaurus), and its meaning is explained by sentences (the definition) that use other words that are themselves explained by other sentences, and so on, in a circular fashion. Linguistic semantics are fundamental to a classical dictionary. Verbs and common nouns (e.g., tree, animal, organ, eat) represent categories that are themselves connected by a dense network of semantic relations such as: « is a part of, » « is a type of, » « belongs to the same context as, » « is the cause of, » « is prior to, » etc. We think and communicate in the human way because our collective and personal memories are organized in general categories connected by semantic relations.
Referential Semantics (word-thing). In contrast to linguistic semantics, referential semantics bridges the gap between a linguistic symbol (signifier and signified) and a referent (an actual individual). When I say that « oaks are trees, » I am specifying the conventional meaning of the word « oak » by placing it in a species-to-genus relationship with the word « tree »; therefore, I am strictly bringing linguistic semantics into play. But, if I say that « That tree in the yard is an oak, » then I am pointing to a real situation, and my proposition is either true or false. This second statement obviously brings linguistic semantics into play since I must first know the meaning of the words and English grammar to understand it. But, in addition to the linguistic dimension, referential semantics are also involved since the statement refers to a particular object in a concrete situation. Some words, such as proper nouns, have no signified; their signifier refers directly to a referent. For example, the signifier « Alexander the Great » refers to a historical figure and the signifier « Tokyo » refers to a city. In contrast to a classical dictionary which defines concepts or categories, an encyclopedic dictionary contains descriptions of real or fictitious individuals with proper nouns such as deities, novel heroes, historical figures and events, geographical objects, monuments, works of the mind, etc. Its main function is to list and describe objects external to the system of a language. It therefore records referential semantics.
Nota bene: A category is a class of individuals, an abstraction. There can be categories of entities, processes, qualities, quantities, relations, etc. The words « category » and « concept » are treated here as synonyms.
Semantics in AI
In computer science, the real references, or individuals (the realities we talk about) become the data while the general categories become the headings, fields or metadata used to classify and retrieve data. For example, in a company’s database, « employee name », « address » and « salary » are categories or metadata while « Tremblay », « 33 Boulevard René Lévesque » and « 65 K $ / year » are data. In this technical domain, referential semantics corresponds to the relationship between data and metadata and linguistic semantics, to the relationship between metadata or organizing categories, which are generally represented by words, or short linguistic expressions.
Insofar as the purpose of computer science is to increase human intelligence, one of its tasks must help us make sense of the flood of digital data and to extract as much usable knowledge as possible from them. To that end, we must correctly categorize data – that is, implement word-things semantics – and organize the categories according to relevant relations which allow us to extract all the actionable knowledge from the data – which corresponds to word-word semantics.
When discussing the subject of semantics in computer science, we must remember that computers do not spontaneously see a word or a sentence as a concept in a certain relation to other concepts in a language, but only as a sequence of letters, or « string of characters ». Therefore, the relationships between categories that seem obvious to humans and that are part of linguistic semantics, must be added – mostly by hand – to a database if a program is to take them into account.
Let’s now examine the extent to which symbolic AI models semantics. If we consider the ontologies of the « Semantic Web » (the standard in symbolic AI), we discover that the meaning of words do not depend on the self-explanatory circularity of language (as in a classical dictionary), but that words points to URIs (Uniform Resource Identifiers) in the manner of referential semantics (as in an encyclopedic dictionary).
Instead of relying on concepts (or categories) that are already given in a language and that appear from the start as nodes of relations with other concepts, the scaffolding of the Semantic Web relies on concepts that are defined separately from each other by means of unique identifiers. The circulation of meaning in a network of signified is discounted in favor of a direct relationship between signifier and referent, as if all words were proper nouns. In the absence of a linguistic semantics based on a common grammar and dictionary, ontologies thus remain compartmentalized. In summary, contemporary symbolic AI does not have access to the full cognitive and communicative power of language because it does not have a language, only a rigid referential semantics.
So why doesn’t AI use natural languages – with their inherent linguistic semantics – to represent knowledge? The answer is well known: natural languages are ambiguous. A word can have several meanings, a meaning can be expressed by several words, sentences have multiple possible interpretations, grammar is elastic, etc. Since computers are not embodied beings imbued with common sense, as we are, they are unable to correctly disambiguate statements in natural language. For its human speakers, a natural language provides a dictionary, which is a net of predefined general categories that are mutually explanatory. This common semantic network enables the description and communication of multiple concrete situations as well as different domains of knowledge. However, because of their irregularities, AI cannot use natural languages to communicate or to teach machines directly. This is why AI remains fragmented today into micro-domains of practices and knowledge, each with its own particular semantics.
The automation of linguistic semantics could open new horizons of communication and reasoning for Artificial Intelligence. To deal with linguistic semantics, AI needs a standardized and univocal language, a code specially designed for machine use and which humans could easily understand and manipulate. This language would finally allow models to connect and knowledge to accumulate. In short, the main obstacle to the development of AI is the lack of a common computable language. This is precisely the problem solved by IEML, a metalanguage which can express meaning, like natural languages, and whose semantics are unambiguous and computable, like a mathematical language. The use of IEML will make AI less costly in terms of human labor, more adept at dealing with meaning and causality, and most importantly, capable of accumulating and exchanging knowledge.
Without language, we would have no access to enquiry, dialogue, or narrative. Language is simultaneously a medium of personal intelligence – it is difficult to think without inner dialogue – and of collective intelligence. Much of society’s knowledge has been accumulated and passed on in linguistic form. Given the role of speech in human intelligence, it is surprising that we have hoped to achieve general artificial intelligence without a computable model of language and its semantics. The good news is that we finally have one.
IEML: A Solution Based on a Semantic Code
The Information Economy Metalanguage
Many advances in computer science come from the invention of a relevant coding system which renders the coded object (number, image, sound, etc.) easily computable by a machine. For example, binary coding for numbers and pixel or vector coding for images. Therefore, we have been working on the design of a code that makes linguistic semantics computable. This artificial language, IEML (Information Economy MetaLanguage) has a regular grammar and a compact dictionary of three thousand words. More complex categories can be constructed by combining words into sentences according to a small set of grammatical rules. These complex categories can in turn be used to define others, and so on, recursively. To sum up, any type of category can be built from a small set of words.
On a linguistic level, IEML has the same expressive capacity as a natural language, and can be translated in any other language. It is also a univocal language: each word of the dictionary has only one meaning (unlike in natural languages) and a concept has only one expression, making its linguistic semantics computable. It is important to note that IEML is not a universal ontology but is indeed a language that can express any ontology, or classification.
On a mathematical level, IEML is a regular language in the sense established by Chomsky: it is an algebra. It is therefore amenable to all sorts of automatic processing and transformations.
On a computer science level, as we’ll see in more detail below, this metalanguage provides a programming language specialized for the design of knowledge graphs and data models.
The IEML Editor
The Information Economy MetaLanguage is defined by its grammar and three thousand word dictionary, which can be found on the website intlekt.io. This metalanguage comes equipped with a digital tool to facilitate its writing, reading and use: the IEML editor.
The IEML editor is used to produce and explore data models. This notion of « model » encompasses semantic networks, semantic metadata systems, ontologies, knowledge graphs, and labeling systems for categorizing training data. The editor contains a programming language to automate the creation of nodes (categories) and links (semantic relationships between categories). This programming language is declarative, which means that it does not ask the user to organize a flow of conditional instructions, but only to describe the desired results.
1. With the IEML editor, the human modeler can draft the categories that will serve as containers (or memory boxes) for different types of data. As said above, if some categories cannot be found in the 3,000 word IEML dictionary, the modeler can create more of them by combining words to make sentences, bringing a lot of refinement to the categorization.
2. From the categories, the modeler then programs the semantic relations (“is a part of”, “is a cause of”, etc.) that will connect the categorized data. Linking between nodes is automated based on the grammatical roles of the categories. The mathematical properties of relations (reflexivity, symmetry, transitivity) are then specified.
3. Once the data has been categorized, the program automatically weaves a network of semantic relations, finally giving the data even more meaning. Data mining, hypertextual exploration and visualization of relationships by tables and graphs will allow end users to explore the modeled content.
Advantages
Several fundamental features distinguish the IEML editor from contemporary data modeling tools: categories and relationships are programmable, and the resulting models are interoperable and transparent.
Categories and relationships are programmable. The regular structure of IEML allows categories to be generated and relationships to be woven functionally or automatically, instead of creating them one by one. This property saves the modeler considerable time. The time saved by automating the creation of categories and relationships more than makes up for the time spent coding categories in IEML, especially since once created, new categories and relationships can be exchanged between users.
The models are interoperable. All models are based on the same three thousand words dictionary and set grammar rules. The models are, therefore, interoperable, meaning that they can easily merge or exchange categories and sub-models. Each model is still customized to a particular context, but models can now compare, interconnect, and integrate.
The models are transparent. Although coded in IEML, models written with the IEML editor are readable in natural language. Since the categories and relations are labeled with words, or with more elaborate sentences in natural languages (and without semantic ambiguity), the models are clearer to both modelers and end-users, therefore aligning with contemporary principles of ethics and transparency.
The user does not need to be a computer scientist or be familiar with the IEML language to learn how to use it successfully; the learning curve is short. Only the grammar (simple and regular) needs to be mastered. The IEML editor could be used in schools and therefore paving the way for a democratization of data literacy.
The IEML Neuro-Semantic Architecture
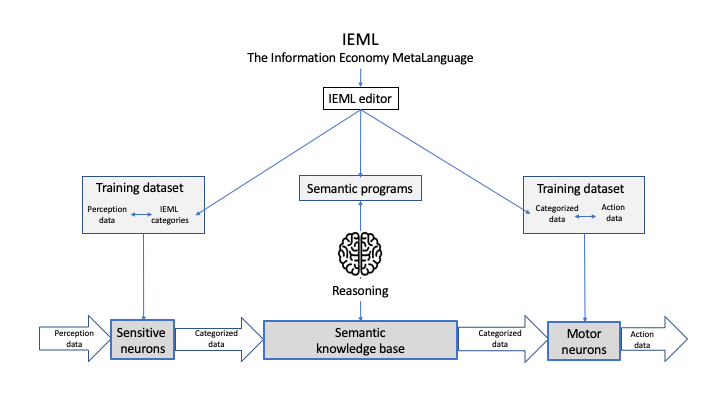
Figure 1: A neuro-semantic architecture for AI
We’ll now propose an AI system architecture based on IEML. This architecture (schematized in Figure 1) is clearly a particular instance of a neuro-symbolic architecture, but it is called neuro-semantic to emphasize that it solves the problem of semantic computation and semantic interoperability between systems.
We must distinguish various types of training data (text, image, sound, etc.) from which various types of neural networks result. Sensory neural networks that have been trained by examples of data categorized in IEML will input information in the system. The data categorized by the sensory neurons is transmitted to the semantic knowledge base. If inconsistencies, errors, or biases are detected, the training data or their conceptualization must of course be revised. Hence, the system must include a dialogue loop between the data annotators who train the neural networks and the engineers who manage the knowledge base.
At the output, motor neural networks transform categorized data into data that control actions, such as text writing, image synthesis, voice output, instructions sent to effectors (robots), etc. These motor neurons are trained with examples that match the categorized data of IEML to motor data. Again, training data and neural networks must be distinguished according to their types.
Memory and Semantic Processing
The knowledge base is organized by a semantic network; therefore, it is preferably supported by a graph database. In terms of interface, this knowledge base is presented as a hypertextual encyclopedia. It also allows the programming of simulations and various dashboards for monitoring and intelligence.
The IEML editor mentioned in the previous section can also be used for tasks other than modeling. In effect, it allows varied read-write operations conditioned by the presence of semantic contents located at certain grammatical roles. When they are coded in IEML, concepts become variables of an algebra, which is obviously not the case when they are expressed in natural language. Therefore, semantic transformations can be programmed and computed. This semantic programming opens the way not only to the classical logical reasoning to which symbolic AI inference engines have accustomed us for decades, but also to other forms of automatic reasoning. Since in IEML semantics is a functional image of syntax, it becomes possible to automate analogical reasoning such as « A is to B what C is to D ». Other semantic operations can also be programmed, such as: selection and search; substitution, insertion, or deletion; extraction of relevant semantic subnetworks; summarization or expansion; inversion, allusion, attenuation, or amplification; extraction or projection of narrative structures, and so on.
Various Applications
Some applications of our IEML neuro-semantic AI architecture are evident: data integration; decision support based on causal models; knowledge management; comprehension and summarization of text; controlled generation of text (unlike GPT3 type systems where text creation is not controlled); chatbots and robotics. We will now briefly comment on two application examples: text comprehension and controlled generation of text.
Regarding controlled text generation, let’s imagine telemetry data, accounting information, medical exams, knowledge test results, etc. as input. As output we can program narrative texts in natural language synthesizing the content of the input data streams: medical diagnoses, school reports, advices, etc.
About text comprehension, let’s first assume the automatic categorization of the content of a document entered into the system. In a second step, the semantic model extracted from the text is written into the system’s memory and integrated with the knowledge that the system has already acquired. In short, Artificial Intelligence systems could accumulate knowledge from the automatic reading of documents. Assuming IEML is adopted, Artificial Intelligence systems would become capable not only of accumulating knowledge, but of integrating it into coherent models and exchanging it. This is obviously a long-term prospect that will require coordinated efforts.
Conclusion: A Humanistic Future for AI
Even if the neuro-semantic architecture proposed above does not entirely dislodge the obstacles in the path of general Artificial Intelligence, it will usher AI in the creation of applications capable of processing the meaning of texts or situations. It also allows us to envisage a market for data labeled in IEML which would stimulate the already booming development of machine learning. It would also support a collaborative public memory that would be particularly useful in the fields of scientific research, education, and health.
Today, the multiplicity of languages, classification systems, disciplinary viewpoints and practical contexts compartmentalizes our digital memory. Yet the communication of models, the critical comparison of viewpoints, and the accumulation of knowledge are essential to human symbolic cognition, a cognition that is indissolubly personal and collective. Artificial intelligence will only be able to sustainably increase human cognition if it is interoperable, cumulative, integrable, exchangeable and distributed. This means that we will not make significant progress in Artificial Intelligence without concurrently striving for a collective intelligence capable of self-reflection and of coordinating itself into a global memory. The adoption of a computable language which functions as a universal system of semantic coordinates – a language that is easy to read and write – would open new avenues for collective human intelligence, including an immersive multimedia interaction in the world of ideas. In this sense, the IEML user community could be the start of a new era of collective intelligence.
Contemporary AI, the majority of which is statistical, tends to create situations where data thinks in place of humans, unaware. In contrast, by adopting IEML, we propose to develop an AI that helps humans to take intellectual control of data in order to extract shareable meaning, in a sustainable manner. IEML allows us to rethink the purpose and operation of AI from a humanistic point of view, a point of view for which meaning, memory and personal consciousness must be treated with the utmost seriousness.
NOTES AND COMMENTED REFERENCES
On the Origins of AI
The term « Artificial Intelligence » was first used in 1956 at a conference at Dartmouth College in Hanover, New Hampshire. Conference participants included computer scientist and cognitive scientist researcher, Marvin Minsky, (Turing Award 1969) and the inventor of the LISP programming language, John McCarthy (Turing Award 1971).
On Cognitive Augmentation
Cognitive augmentation (rather than imitation of human intelligence) was the primary focus of many computer science and Web pioneers. See for example:
– Bush, Vannevar. « As We May Think. » Atlantic Monthly, July 1945.
– Licklider, Joseph. « Man-Computer Symbiosis. » IRE Transactions on Human Factors in Electronics, 1, 1960, 4-11.
– Engelbart, Douglas. Augmenting Human Intellect. Technical Report. Stanford, CA: Stanford Research Institute, 1962.
– Berners-Lee, Tim. Weaving the Web. San Francisco: Harper, 1999.
On the History of Neural AI
Many people recognize Geoffrey Hinton, Yann Le Cun and Yoshua Benjio as the founders of contemporary neural AI. But neural AI began as early as the 1940s in the 20th century. A brief bibliography is provided below.
– The first theoretical paper on neural IA was published in 1943: McCulloch, Warren, and Walter Pitts. “A Logical Calculus of Ideas Immanent in Nervous Activity.” Bulletin of Mathematical Biophysics, 5, 1943: 115-133. Warren McCulloch published several papers on this themes that were collected in Embodiments of Mind. Cambridge, MA: MIT Press, 1965. I wrote a paper on his work: Lévy, Pierre. “L’Œuvre de Warren McCulloch.” Cahiers du CREA, 7, Paris, 1986, p. 211-255.
– Frank Rosenblatt is the inventor of the Perceptron, which can be considered as the first machine learning system based on a neuro-mimetic network. See his book Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms, published in 1962 by Spartan Books.
– Marvin Minsky’s 1954 Ph.D. dissertation was entitled, « Theory of neural-analog reinforcement systems and its application to the brain-model problem. » Minsky would criticize Frank Rosenblatt’s perceptron in his 1969 book Perceptrons (MIT Press) written with Seymour Papert and would later continue the symbolic AI research program. Also by Minsky, The Society of Mind (Simon and Schuster, 1986) summarizes well his approach of human cognition as emerging from the interaction of multiple cognitive modules with varied functions.
– Heinz von Foerster was the secretary of the Macy Conferences (1941-1960) on cybernetics and information theory. He was director of the Biological Computer Laboratory at the University of Illinois (1958-1975). His main articles are collected in Observing Systems: Selected Papers of Heinz von Foerster. Seaside, CA: Intersystems Publications, 1981. I studied closely the research done in this lab. See : Lévy, Pierre “Analyse de contenu des travaux du Biological Computer Laboratory (BCL).” In Cahiers du CREA, 8, Paris, 1986, p. 155-191.
– In the eighties of the XX° century, let’s notice the publication of the landmark book of McClelland, James L., David E. Rumelhart and the PDP research group. Parallel Distributed Processing: Explorations in the Microstructure of Cognition. 2 vols. Cambridge, MA: MIT Press, 1986.
– This same year 1986, Rumelhart, David E.; Hinton, Geoffrey E.; Williams, Ronald J. published an important paper: « Learning representations by back-propagating errors » in Nature 323 (6088): 533-536, 9 October 1986. Hinton was later recognized for his pioneering work with a Turing Award along with Yann LeCun and Joshua Benjio in 2018. One of their most cited common paper is: Y LeCun, Y Bengio, G Hinton “Deep learning” Nature, 521, 436–444, 2015.
The Critique of Statistical AI
Concerning the critique of statistical IA, this text resumes some of the arguments put forward by researchers like Judea Pearl, Gary Marcus and Stephen Wolfram.
– Judea Pearl received the Turing Award in 2011 for his work on causality modeling in AI. He and Dana Mackenzie wrote The Book of Why, The new science of cause and effect, Basic books, 2019.
– Gary Marcus wrote in 2018 a seminal article: « Deep learning, a critical appraisal » https://arxiv.org/pdf/1801.00631.pdf?u (Accessed on August 8, 2021). See also Gary Marcus’ book, written with Ernest Davis, Rebooting AI: Building Artificial Intelligence We Can Trust, Vintage, 2019.
– Stephen Wolfram is the author of the Mathematica software and the brain behind the Wolfram Alpha search engine. See his 2016 interview for Edge.org « AI and the future of civilisation » https://www.edge.org/conversation/stephen_wolfram-ai-the-future-of-civilization Accessed on August 8, 2021.
– In addition to Judea Pearl’s work on the importance of causal modeling in AI, let’s remember philosopher Karl Popper’s theses on the limits of inductive reasoning and statistics. See, in particular, Karl Popper, Objective Knowledge: An Evolutionary Approach. Oxford: Clarendon Press, 1972.
On Contemporary Neural AI
– On the currently most used of all the natural language processing model, called BERT, see: https://en.wikipedia.org/wiki/BERT_(language_model) Accessed on August 8, 2021.
– The recent report by the Center for Research on Foundation Models (CRFM) at the Stanford Institute for Human-Centered Artificial Intelligence (HAI), is entitled: On the Opportunities and Risks of Foundation Models. It begins with this sentence: « AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. » https://arxiv.org/abs/2108.07258
– On Open AI see: https://openai.com/blog/gpt-3-apps/ and https://www.technologyreview.com/2020/08/22/1007539/gpt3-openai-language-generator-artificial-intelligence-ai-opinion/ Sites visited on August 16, 2021.
On Contemporary Symbolic AI
– Integrating existing knowledge into AI systems is one of the main goals of Stephen Wolfram’s « Wolfram Language ». See https://www.wolfram.com/language/principles/ Accessed on August 16, 2021.
– On the Semantic Web, see https://www.w3.org/standards/semanticweb/# and https://en.wikipedia.org/wiki/Semantic_Web Accessed on August 8, 2021
– On Wikidata see: https://www.wikidata.org/wiki/Wikidata:Main_Page Accessed on August 16, 2021.
– On Douglas Lenat’s Cyc project see: https://en.wikipedia.org/wiki/Cyc Accessed on August 8, 2021.
On the Neuro-symbolic Perspective
– « AI Research and Governance Are at a Crossroads » by Dieter Ernst. https://www.cigionline.org/articles/ai-research-and-governance-are-crossroads/ Accessed on August 8, 2021.
– Neurosymbolic AI: The 3rd Wave, Artur d’Avila Garcez and Luis C. Lamb, December, 2020 (https://arxiv.org/pdf/2012.05876.pdf) Accessed on August 8, 2021.
– On the neuro-symbolic fusion, see also the recent report from Stanford University « 100 Year Study on AI » which identifies the neuro-symbolic hypothesis as one of the keys to advancing the discipline. https://ai100.stanford.edu/ Accessed on September 20, 2021.
On Semantic Interoperability
– All semantic metadata editors claim to be interoperable, but it is generally an interoperability of file formats, the latter being effectively ensured by Semantic Web standards (XML, RDF, OWL, etc.). But in this text, I am talking about the interoperability of semantic models themselves (we are talking here about architectures of concepts: categories and their relations). It is important to distinguish semantic interoperability from format interoperability. Models written in IEML can be exported in standard semantic metadata formats such as RDF, JSON-LD or Graph QL. On the notion of semantic interoperability, see: https://intlekt.io/2021/04/05/outline-of-a-business-model-for-a-change-in-civilization/ Accessed on January 10, 2022.
On Chomsky and Syntax
One of the first researchers to have undertaken a mathematization of languge is Noam Chomsky. See his Syntaxic Structures. The Hague and Paris: Mouton, 1957 and the paper he wrote with Marcel-Paul Schützenberger. « The Algebraic Theory of Context-Free Languages. » In Computer Programming and Formal Languages. Ed. P. Braffort and D. Hirschberg. Amsterdam: North Holland, 1963. p. 118-161. For a more philosophical approach, see Chomsky, Noam. New Horizons in the Study of Language and Mind. Cambridge, UK: Cambridge UP, 2000. To understand how IEML continues several trends of the XX° century linguistic research see my article on “The linguistic roots of IEML”: https://intlekt.io/the-linguistic-roots-of-ieml/ Accessed on January 10, 2022.
On Proper Names
I adopt here the position of Saul Kripke who is followed by most philosophers and grammarians. See, by Saul Kripke, Naming and Necessity, Oxford, Blackwell, 1980. See my recent blog entry on this subject: https://intlekt.io/proper-names-in-ieml/ Accessed on January 10, 2022.
Pierre Lévy on IEML
– « Toward a Self-referential Collective Intelligence: Some Philosophical Background of the IEML Research Program. » Computational Collective Intelligence, Semantic Web, Social Networks and Multiagent Systems, ed. Ngoc Than Nguyen, Ryszard Kowalczyk and Chen Shyi-Ming, First International Conference, ICCCI, Wroclaw, Poland, Oct. 2009, proceedings, Berlin-Heidelberg-New York: Springer, 2009, pp. 22-35.
– « The IEML Research Program: From Social Computing to Reflexive Collective Intelligence. » In Information Sciences, Special issue on Collective Intelligence, ed. Epaminondas Kapetanios and Georgia Koutrika, vol. 180, no. 1, Amsterdam: Elsevier, 2 Jan. 2010, pp. 71-94.
– The philosophical and scientific considerations that led me to the invention of IEML have been amply described in La Sphère sémantique. Computation, cognition, économie de l’information. Hermes-Lavoisier, Paris / London 2011 (400 p.). English translation: The Semantic Sphere. Computation, Cognition and Information Economy. Wiley, 2011. This book contains an extensive bibliography.
– The general principles of IEML are summarized in: https://intlekt.io/ieml/ Accessed on January 10, 2022.
– On the IEML grammar, see: https://intlekt.io/ieml-grammar/ Accessed on January 10, 2022.
– On the IEML dictionary, see: https://intlekt.io/ieml-dictionary/ Accessed on January 10, 2022.
Other Relevant References by Pierre Lévy
– L’intelligence collective, pour une anthropologie du cyberespace, La Découverte, Paris, 1994. English translation by Robert Bonono: Collective Intelligence, Perseus Books, Cambridge MA, 1997.
– Les systèmes à base de connaissance comme médias de transmission de l’expertise » (knowledge-based systems as media for transmission/transfer of expertise), in Intellectica (Paris), special issue on « Expertise and cognitive sciences », ed. Violaine Prince. 1991. p. 187 to 219.
– I have analyzed in detail the work of knowledge engineering in several cases in my book, De la programmation considérée comme un des beaux-arts, La Découverte, Paris, 1992.
[1] “AI Research and Governance Are at a Crossroads” by Dieter Ernst. https://www.cigionline.org/articles/ai-research-and-governance-are-crossroads/ August 8th, 2021.

Un avis sur « IEML: Towards a Paradigm Shift in Artificial Intelligence »